- 專欄
文章專區
2019-07-01電腦如何擊敗頂尖棋士?淺談AlphaGo人工智慧系統
595 期
Author 作者
顏士淨/國立東華大學資訊工程系教授,從事人工智慧、機器學習、電腦對局等研究,圍棋棋力為業餘六段。
2016 年 Google DeepMind 團隊的 AlphaGo 擊敗南韓九段圍棋棋王李世乭,震撼全世界,可說是人工智慧的重要里程碑。AlphaGo 主要以人工智慧深度學習的技術開發,並透過強化式學習的方式提高棋力。DeepMind在 2014年開始網羅機器學習與電腦圍棋菁英,包括席維爾(David Silver)、黃士傑(Aja Huang)與麥迪遜(Chris J. Maddison)等專家學者,加上充沛的計算資源與大量的資訊人才,不但影響圍棋的發展,也讓很多人開始思考人工智慧對人類未來的影響。
AlphaGo能擊敗人類,主要是模仿人類棋士的空間比對與思考,其採用 3 種先進的機器學習技術:深度學習(Deep Learning, DL)、強化式學習(Reinforcement Learning, RL)及深度強化式學習(Deep Reinforcement Learning, DRL)。以下將分別敘述這 3 種機器學習技術。
越複雜越好——深度學習
AlphaGo 所使用的深度學習技術是一種類神經網路(Neural Network)技術,早在 20 世紀中期,就有許多學者提出類神經網路的概念,而自 1980 年起,類神經網路開始實際應用在解決現實世界問題。一般的類神經網路可分為輸入層、輸出層與隱藏層(圖一),輸入層為圖片,輸出層為圖片種類判斷,其餘則為隱藏層。而所謂深度學習網路,其中的深度就是指隱藏層的個數,增加深度可使網路有能力處理更複雜的問題。在相對複雜的圍棋布局中,AlphaGo 的深度學習網路深度設定為 13 層。而深度學習類神經網路原本用於圖形辨識問題,圖一中的深度學習網路便是用於辨識圖形,並予以分類。2011 年起,GPU 繪圖顯示晶片因為可以充分利用大量平行化的運算特性,大幅提高效能至實用階段。
圍棋方面,人工智慧學界從 2008 年起就有將深度卷積式類神經網路(Deep Convolutional Neural Network, DCNN)運用在圍棋的研究。而電腦圍棋界也有許多人將 DCNN 直接應用在圍棋程式裡面,趨勢科技創始人張明正曾經在 2015 年,邀請圍棋棋士王銘琬、趨勢科技的工程師與東華大學共同成立 GoTrend 團隊,同時也研究 DCNN 在圍棋的應用,在 2015年日本 UEC電腦圍棋比 賽中獲得不錯的表現。而在 2016年的UEC比賽中,前8名有7隊都是以深度學習技術開發。AlphaGo 團隊也採用深度學習進行辨識棋型,並預測高段棋士的著手。......【更多內容請閱讀科學月刊第 595 期】
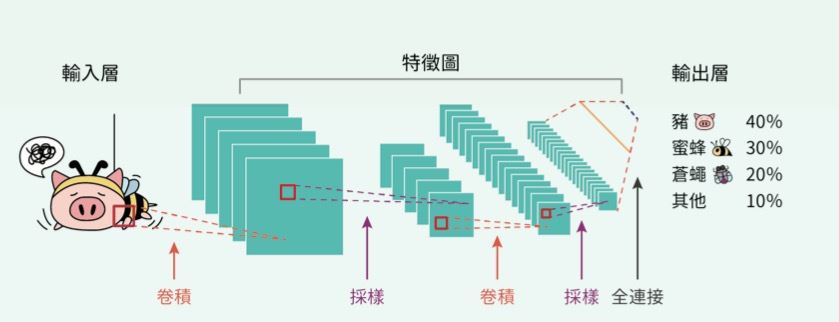
圖一:深度學習技術,輸入層為圖片,輸出層為圖片的判別,其餘則為隱藏層。能用於辨識圖形,並進行分類。