- 評論
文章專區
2024-03-01如何整合、管理海量資料? 數位經濟發展下的資料治理
651 期
Author 作者
莊宜勳/成功大學資訊工程系助理研究員;郭耀煌/成功大學資訊工程系特聘教授
Take Home Message
•資料治理是數位經濟的基礎,為確保資料能符合規範並達成預期目標,須先定義資料標準、規範、問責機制等原則。
•AI服務中資料治理須遵守服務穩健、隱私保護、公平、審計等準則,並預設組織內成員參與意願低、資料偏移等問題的解方。
•智慧城市的資料治理兼具資料整合、大量儲存、公私部門共享並提供多元服務,例如臺北大數據中心、新加坡資料生態系等機制。
隨著ChatGPT的浪潮席捲全球,大量基於人工智慧(artificial intelligence, AI)的服務出現,為人們帶來更便利的生活,也讓AI相關產業迎來了另一個春天。然而,這些服務之所以能順利運行,基本都建構於海量的資料之上。因此除了服務本身的營運之外,這些海量資料的取得、儲存、分享、管理都各自擁有複雜的產業生態,進而共同形成一個龐大的數位經濟體系。
事實上,早在2016年世界各國就注意到數位經濟的巨大潛力,於是當年的世界經濟論壇(World Economic Forum, WEF)便以「數位經濟再創新」作為全球資訊科技報告的年度主題,希望能藉由發展新興技術與應用促進數位創新,進一步推動數位經濟成長。而如何有效治理數位經濟的基石「海量資料」,也就成為了數位經濟的重中之重。
資料治理vs資料管理
一般來說,如何管好資料是一門傳統的學問。然而,有別於資料管理只討論管控資料的技術,資料「治理」考量的範圍更加全面,主要為制定各種原則和策略,以確保在資料的生命週期間(收集、儲存、使用、保護、建檔、銷毀)均能符合組織規範,並達成預期目標,包含:
▪定義標準與架構:定義資料與服務的結構。在資料結構方面,須先統整組織內所有資料,包括原生資料(raw data)與後設資料(meta data),例如標準化資料的術語、類型、格式、品質需求、因果關聯等資訊,以確保系統內資料的完整性與一致性,有利於後續的資料互通。在服務結構方面則是須定義此服務下所有參與的成員、群組設定、權責關係、權限需求。
▪定義資料的規範:資料治理最核心的部分就是定義規範與流程。一般來說,資料在不同的生命週期有各自應滿足的需求。例如在收集圖資時針對品質定義最低解析度;在儲存資料時先定義可得性(availability)與存取效能的需求;在使用資料時定義資料使用與呈現的方式;在保護資料時分別考量不同使用者的使用權限並保存存取紀錄;在資料建檔時定義索引方式;在銷毀階段定義資料清理(data housekeeping)的頻率與流程。
▪規劃問責機制並持續追蹤治理狀態:資料治理不僅是企業內部資訊部門與決策單位的責任,它的成效很大部分取決於全體使用者參與的程度。因此,資料治理尚需妥善的問責機制並確實執行,才能內化到公司治理中,成為企業文化的一部分。此外,不同組織對於資料治理的需求不盡相同,而資料治理的規畫更不可能一蹴而就,必須持續收集成員的回饋意見並加以修正,才能得到最適合的資料治理機制。
AI服務中資料治理的法規與準則
然而,在定義資料治理規範之前,也需要對於國內外相關法規有更進一步的了解。例如歐盟針對服務提供商提出了《一般資料保護規則》(GeneraData Protection Regulation, GDPR),要求保護資料內個人可識別資訊的隱私,另外又定義了被遺忘權(right to be forgotten)與資料可攜權(right to data portability),前者要求在資料擁有者要求之下,服務提供商必須確保能夠刪除所有個人資料的任何連結、副本或複製品,後者則要求能夠將個人資料以通用的方式轉移到指定的服務中。此外,歐盟議會發布了《可信賴人工智慧倫理準則》(Ethics Guidelines for Trustworthy AI),具體描述提供AI相關服務應遵守的行為準則,其中有多項與資料治理密切相關:
▪服務穩健性:系統必須能夠穩健地提供服務,並提出妥善備援計畫。因此,規劃資料治理機制須達到數位韌性(digital resilience)的要求,例如以Web3概念建構韌性網路服務,防止服務被阻斷服務攻擊或資料被惡意人士挾持。
▪資料安全與隱私保護:資料治理機制必須在「保護資料安全與使用者隱私以符合GDPR等個資相關法規」的前提下讓合法使用者取用資料。
▪公平與反歧視:AI服務很可能因為參與訓練的資料分布不平均,而造成部分群體的分析偏差。一個好的資料治理機制應該協助不同組織間資料的互通,提升資料共享意願並舒緩資料孤島的現象,藉此取得更大量且多元的資料,避免偏見與歧視。
▪審計與問責:資料治理應能提供資料審計功能(auditability),以便後續舉證釐清責任歸屬。
智慧城市的資料治理
一直以來,智慧城市都是AI服務最好的展場,擁有最多元的服務、最複雜的參與角色、權限規畫、最大量的資料儲存。因此智慧城市的資料治理也最為困難,以下介紹四個城市的資料治理機制:
新加坡:為了催生更多智慧城市創新應用,新加坡政府由法制面、環境面、技術面推動資料治理,以促進企業、政府、個人間的資料順利流通,並降低資料收集、處理、利用的成本。首先,政府規劃公私資料協作框架與技術堆疊(Singapore Government Technology Stack, SGTS),再建立可信任的資料中介機構以利公私資料交換。最終形成跨公私部門的資料生態系(Core Operations, Development Environment, and eXchange, CODEX),並由資通訊媒體發展局(Infocomm Media Development Authority, IMDA)及個人資料保護委員會(Personal Data Protection Commission, PDPC)發布資料共享框架,指導公私之間建立資料共享夥伴關係(圖一)。
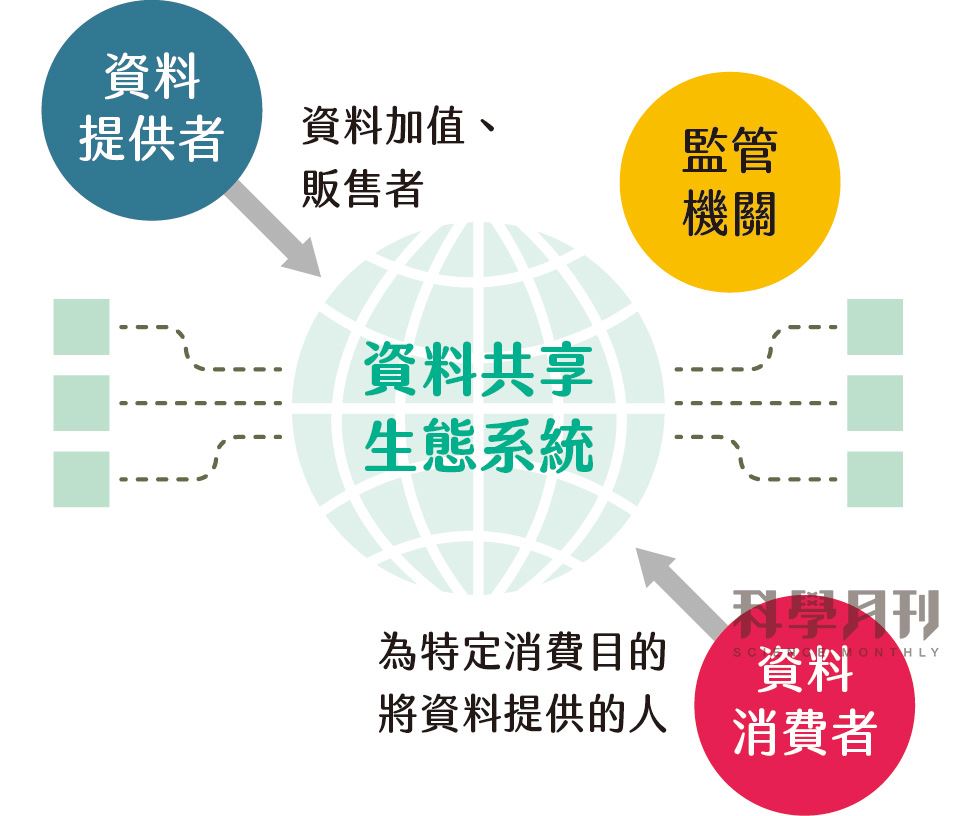
圖一|新加坡資料共享生態系
(資料來源:新加坡資通發展局)
美國芝加哥:芝加哥市政府期許能以開放資料協助政府與民間一同打造智慧城市。為此,彭博慈善基金會(Bloomberg Philanthropies)資助成立「Chicago's SmartData Platform」將市府各部門的資料,包括能源、用水、社福、公共安全等,進行標準化與整合。同時提供資料分析、可視化等AI工具協助大學、研究機構、業界了解和利用資料,以開發更多創新的智慧城市服務。
法國南特:身為歐盟「mySMARTLife」計畫中的燈塔城市,南特市希望藉AI服務打造永續城市(Sustainable City),利用資料治理平臺「Nantes Urban Platform」收集、統整政府各部門資料,並結合城市物聯網數據,讓市府、市民、企業同心協力面對環境永續、氣候變遷等城市的難題。
臺北:臺北市於2022年1月成立臺北大數據中心,負責推動臺北市的都市資料治理。此中心管理了十年來臺北市政府不斷推動且累積的2800多項開放資料集,包含即時交通路況、醫療量能、水情資訊、空氣品質狀況、道路監控影像等,除了提供市府在疫情、交通、人流、社會安全等議題的決策參考,也希望透過與民間與社群之間的交流回饋,達到開放資料的正循環效益(圖二)。
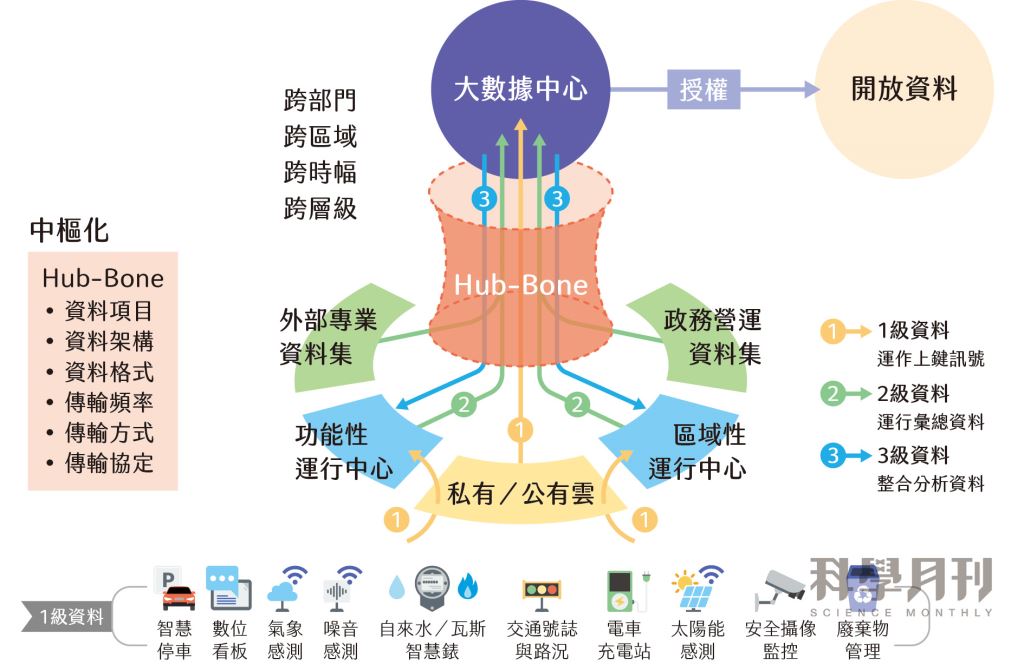
資料治理的挑戰與解方
任何管理機制的推動都不可避免經歷波瀾,若預先分析問題癥結,並規劃好以下列出的應對方案,將有助管理機制的順利導入:
▪成員參與意願低落:在組織內推行資料治理時,首先會面臨成員參與意願低落的問題,且多數成員會過度依賴技術團隊。然而,如前所述,資料治理與資料管理的差距甚大,並非技術團隊單方面即可促成。為此,推行資料治理時應首重互惠性,針對每個成員的工作職責,宣導資料治理對自身的好處,並依此規劃成員應配合的方式與時程。
▪資料偏移問題:不同組織根據各自的特性,所擁有的資料不盡相同,甚至不同族群所能收集到的資料量也不太一樣。例如罕見疾病或偏鄉學童的資料量相較於正常人有一段落差,如此將形成嚴重的資料偏移。過去缺少了有效的資料治理機制和資料經濟體系,不同組織間共享資料的意願薄弱,形成嚴重的資料孤島。此情況不但容易造成分析失準,更甚者可能加劇城鄉發展落差。因此最佳的解決方案是建立妥善的資料治理機制,並搭配可靠的資料交易平臺。此舉不僅可以舒緩提供資料的疑慮,更能增加提供資料的動機。
▪法規問題:資料治理須先配合相關法律的規範。最基本的規範是各國的個資保護法,而不同領域也有各自必須遵守的規範,例如醫療相關資料須符合《健康保險流通與責任法案》(Health Insurance Portability and Accountability Act, HIPAA)。資料治理機制必須根據資料所欲分享的應用領域或服務目的,做出差異化的存取權限設計。
以「信任」為治理核心
資料治理的核心在於建立信任,好的資料治理能獲得資料擁有者的信任,使資料擁有者更有意願分享資料,既可活化庫存資料,也避免形成資料孤島;還有助於取得使用者的信任,讓數位應用更加普及並進一步活絡數位經濟;更能讓政府受到人民的信任,以更透明的方式、更迅速的反應做出更適當的決策,除了建立好與民溝通的橋樑,也簡化了決策的流程。因此,在這個資料為王的時代,臺灣必須積極落實資料治理,由政府單位帶頭民間企業跟進,才能為數位應用發展奠定良好的基礎,進而達到數位永續的願景。