- 封面故事
- 2013年
- 518期 - 人工智慧的起源—人工辨識(2月號)
文章專區
2013-02-01語音辨識
518 期
Author 作者
陳柏琳/任教台灣師範大學資訊工程學系。
語音(Speech)長久以來是人與人之間最自然且最方便的溝通方式。隨著電子數位科技的蓬勃發展以及無線通訊與網際網路的創新普及,傳統的桌上型電腦不再是人們唯一主要的資訊存取平台,有可能取而代之的是各式各樣的手攜式設備(如智慧型手機、平板電腦等)以及更多的行動載具與家電產品,這些設備將變成是可以運算、通訊與上網的智慧型設備,而且朝輕薄短小的趨勢演進發展。同時,將不是每種設備都具有螢幕、鍵盤和滑鼠等這些人們習以為常的輸出入裝置;就算是有,它們也將不若過去在桌上型電腦使用時那樣地方便。於是「語音」這種人類最自然且最容易使用的溝通媒介,將扮演著人類與各式智慧型設備間最主要的人機介面,徹底改變人類長久以來與其之互動方式,進而擴展人類對各種智慧型設備的使用層面與資訊存取模式。例如,近期蘋果電腦推出的Siri、Google 推出的Voice Search (Google Now)、以及韓國三星所推出的Samsung S Voice 等人機互動服務,都是使用語音辨識(Speech Recognition) 技術, 將智慧型手機使用者的口語指令轉寫成文字後,透過資訊檢索(Information Retrieval) 或問答處理(Question Answering),從網際網路(Internet)或資料庫(Database)中搜尋所需要的資訊服務,諸如電話簿(黃頁)、氣象、股市、餐飲、景點、以及新聞等。
另一方面,日常生活中可以存取與使用的多媒體(Multimedia) 影音資訊愈來愈多,例如電視與電影節目(例如YouTube)、課程與演講錄影、以及數位典藏等。這些多媒體資訊可以從網路上大量地取得,已經成為傳統文字資訊(Text Information)外,被社會大眾廣泛使用的資訊來源。顯而易見的是,在上述的絕大部分多媒體資訊中,語音可以說是最具語意的主要內涵之一,當播放出多媒體的語音資訊或是顯示出透過語音辨識所產生的轉寫文字,我們就可以大概地瞭解其中所要傳達的主題或概念。因此,語音辨識技術對多媒體資訊分析與理解也扮演著相當重要的角色,近年來在國際上有相當多從事多媒體語音內涵自動辨識的研究與應用被發表,常以新聞、電話交談內容、演講、會議討論、以及口述歷史典藏的語音辨識為主。
總體來說,語音辨識基本上包括了三個主要模組:特徵擷取、聲學比對、語言解碼,如圖一所示。語音特徵擷取將數位語音訊號切割成重疊的音框(Frames),進行語音特徵向量擷取;聲學比對將已建立好的聲學模型(如隱藏式馬可夫模型(Hidden Markov Models, HMM), 可以是音素(Phoneme)、音節(Syllable) 或詞(Word)為單位)與輸入語句中每一個可能語音段落的特徵向量作比對,計算聲學相似度(Acoustic Likelihood); 語言解碼則是依據所有可能候選詞段落的聲學相似度與候選詞間的語言模型限制(如使用N連語言模型,根據前面的N -1 詞歷史(Word History) 來預測下一個詞可能出現的機率),進行解碼找出機率最大(最有可能)的文句。
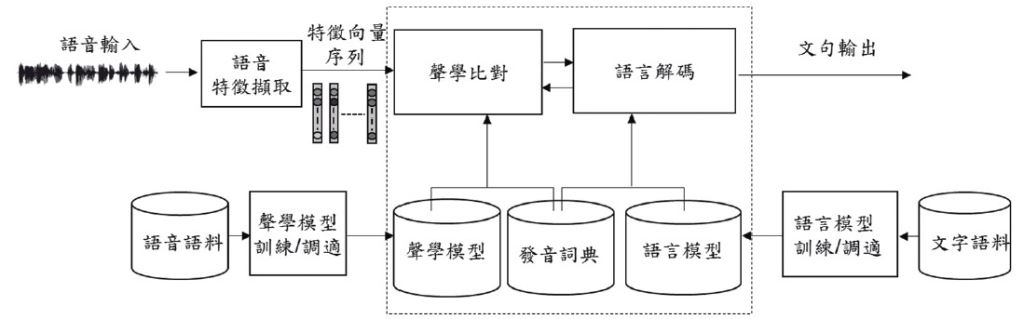
圖一:大詞彙連續語音辨識流程。
語音特徵擷取
(Speech Feature Extraction)
語音特徵擷取以考量人耳聽覺感受出發的梅爾倒頻譜係數(Mel-frequency Cepstral Coefficients, MFCC) 以及感知線性預測分析(Perceptual linear predictive analysis, PLP) 為目前兩種主流的語音特徵向量擷取方法;配合上它們的一階與二階時間軸導數(Time Derivatives)、以及簡單的特徵平均值與變異數正規化(Mean and Variance Normalization)等強健性(Robustness)處理後,可以在一般語音辨識應用上得到不錯的效果。近幾年則陸續有研究嘗試針對這些語音特徵向量作進一步處理,最常見的是使用線性鑑別分析(Linear Discriminant Analysis, LDA) 等,對語音特徵向量作線性轉換並降低維度只保留具有鑑別力的特徵成分,或者將語音特徵向量投射到高維度特徵空間作線性鑑別分析,解決在原特徵空間可能存在的非線性鑑別問題。另外,有許多研究發展自動偵測語音訊號中所富含的許多線索與屬性,例如音高輪廓(Pitch Contour)、能量集中程度(Energy Concentration)、音素與詞彙邊界(Phone and Word Boundaries)等,以自下而上(Bottom-up)方式將這些線索與屬性運用於語音辨識過程中。近期,亦有許多研究單位應用新穎的深層類神經網路(Deep Neural Networks, DNNs)語音辨識架構,它含有許多層的非線性隱藏單元(Nonlinear Hidden Units),並直接以梅爾頻譜率波器(Mel-frequency Filterbanks)輸出的語音特徵做為其輸入層的輸入,在許多的語音辨識任務都展現了較使用MFCC 與PLP 特徵有相當不錯的語音辨識效能提升。……【更多內容請閱讀科學月刊第518期】