- 專欄
文章專區
2020-01-01把歌曲變成伴唱帶 如何從樂曲中分離音樂與人聲
601 期
Author 作者
蘇黎/臺大電機系及數學系雙學士,臺大電信所博士。目前為中研院資訊所助研究員,研究興趣為音樂人工智慧。
對於愛唱卡拉OK(Karaoke)或音樂迷來說,如果有個系統或軟體就能將音樂檔的人聲與背景音分離,就能隨時高歌一曲或編輯音樂了。但電腦軟體處理音樂的方式與人腦不同, 需要在音樂的訊號中找尋及分辨進行分析,而近年來的卷積式神經網路,也使音訊分離的能力更上層樓,未來可透過更多訓練資料提升準確度。
在一場喧囂的派對中,高分貝的電子音樂似乎蓋過了所有的聲音。孤獨的你置身其中,只看見四周的人們互相交談,卻聽不見彼此說話的內容。但他們依然持續交談著,臉上的表情充分顯示自己聽得懂彼此訴說的話語。此情景並不罕見,人們往往能夠專注在特定對象的聲音上,而忽略其它噪音干擾,這即是雞尾酒會效應(cocktail party effect)。類似雞尾酒會效應的能力也出現在日常的聽覺經驗中,例如收聽流行歌曲時,有時候會特別注意主旋律的人聲,而當陶醉於歌手的聲線時,人的聽覺或多或少能把伴奏的成分排除。
而讓機器自動辨識吵雜的環境中說話的內容,在伴奏中分析歌手的音高與音色,甚至將人聲及伴奏的樂器聲分離,都是音訊處理與人工智慧領域中探索久遠的技術。這些技術在音樂工程中有相當多的應用,其中一個重要的例子就是本文的主題:分離單聲道(mono-channel), 將音樂中的人聲及作為伴奏器樂聲進行聲源分離(source separation)。相信這對許多愛唱卡拉OK的朋友來說,把完整版的音樂檔轉成卡拉OK版本,是長久以來所期待的夢想。過往數十年來所發展的工具大多有人聲分得不夠乾淨的問題,如今由於深度學習(deep learning)的發展,才有越來越多方便好用的單聲道聲源分離工具問世。
不同聲源的聲源分離
在進入正題之前,必須先釐清聲源分離問題的範疇。首先,聲源分離問題與雞尾酒會效應中所指的音高或音色的辨識問題不同。當辨識吵雜環境中對方說話的內容,指的是直接「聽見」或「聽懂」特定的聲源;而聲源分離則要求「復現」此聲源,例如在派對中聽著歌手的高音,聽者可立即知道歌手所唱的那是哪一首歌,甚至能精準地跟著唱出還原每個音高與歌詞,但此精準的辨識能力與復現歌手唱歌的原始訊號無關。事實上,聽者完全不需要、也無法因為聽懂音樂就能把音樂訊號處理乾淨,更無法因此復現每個聲部的訊號。相對而言,機器即便是能復現原音,也未必能像人類理解原音的內容與意義。
其次,必須進一步規範何謂一個獨立而特定的聲源。試比較下列兩種情形:一名歌手獨唱一段旋律與一大群歌手合唱同一段旋律,前者固然是一個聲源,但後者則是多個聲源?還是依然是同一個聲源,但整體而言音色是否不同?假如是多個聲源,那聽者有辦法聽出每一位歌手的聲音嗎?假如無法,有可能復現每一位歌手的歌聲嗎?當歌手與歌手之間音色高度相似,演唱內容雷同,則似乎很難界定每位歌手彼此都是不同的聲源,而彼此的聲音可以被分離。換句話說,何謂一個獨立而特定的聲源,是由彼此的音色及演唱內容所決定,而以訊號處 理的語言來說,則是藉由訊號特徵(feature)所決定。 因此,筆者將從訊號特徵的討論出發。
找尋聲波中的訊號特徵
接下來的挑戰,就是如何從聲波中找出訊號特徵。一般人平常所聽到的音樂,都是由不同波形的聲波訊號疊加而成,如圖一顯示的是一個人聲與鋼琴各自的訊號波形及兩個訊號疊加的結果。讀者可以觀察到這種訊號的規律性:每隔一個週期(period)的時間,會觀察到相似的波形(wave shape), 而人類的聽覺機制中,不同週期可對應不同的音高,不同的波形則能對應到不同的音色。但觀察兩個聲波的疊加時,其實很難從疊加後的波形回推原本的波形。換句話說,一般人很難從波形本身找到足夠的訊號特徵描述兩種聲音。
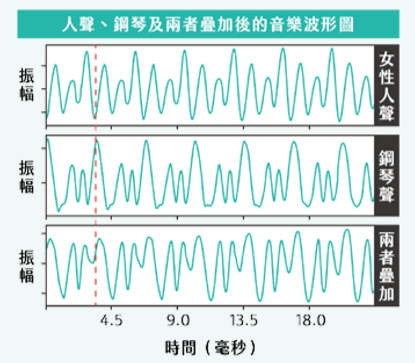
圖一:音樂波形截錄範例。上圖為女性人聲音高為D4的波形;中間為鋼琴音高為D4的波形;下方則為人聲與鋼琴的疊加。
在A0 = 440 Hz時,D4的基礎頻率為293.67 Hz,相當於週期3.405 毫秒,如紅色虛線所標示的訊號週期。
此時就需要利用頻譜分析(spectral analysis)。頻譜分析中最重要的工具是傅立葉變換(Fourier transform), 傅立葉變換能夠將週期性訊號,表示成各種不同振幅與頻率正弦波訊號的加總。……【更多內容請閱讀科學月刊第601期】